


Ever wanted to make your own programming language or wondered how they are designed and built?🤔
This article explains the process behind designing your own programming language...
by the way not with whole coding stuff...
we will see how the interpreter is implemented. Let's first see what is an interpreter at its core.
In simple terms- an INTERPRETER basically takes in the source code and executes it immediately. It runs programs “from source”. That's it.
Let's get into the steps then,
Parts of a Language
Even though today’s machines are literally a million times faster and capable to store more data than it was before 5 decades, the way we build programming languages is still unchanged.
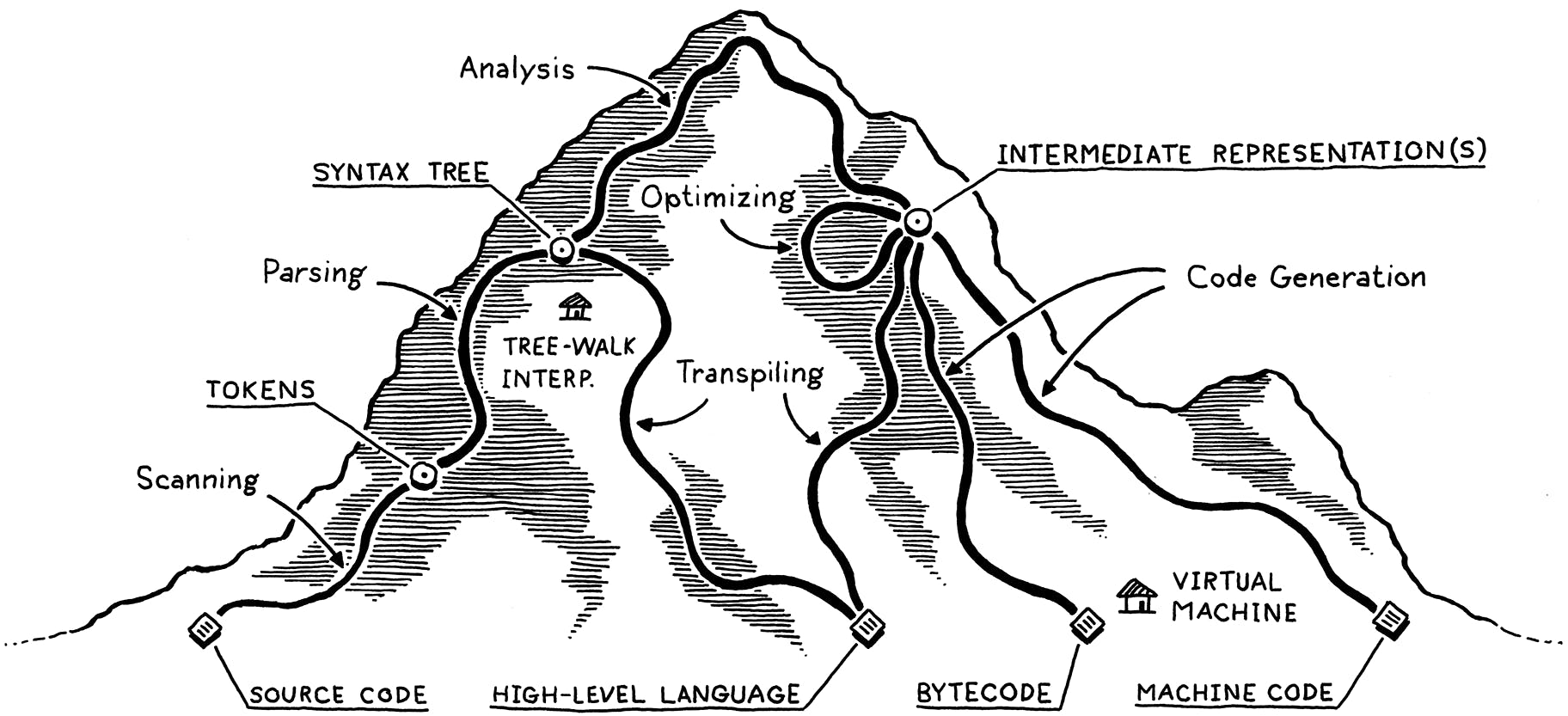
Let us have the above mountain as our reference.
Front-End of the implementation:
Scanning
The first step is scanning, also known as lexing.
A scanner (or lexer) takes in the linear stream of characters and chunks them together into a series of something more like “words”. In programming languages, each of these words is called a token. Some tokens are single characters, like ( and ,. Others may be several characters long, like numbers (123), string literals ("hi!"), and identifiers (min).
Some characters in a source file don’t actually mean anything. Whitespace is often insignificant, and comments, by definition, are ignored by the language. The scanner usually discards these, leaving a clean sequence of meaningful tokens.
Parsing
The next step is parsing. This is where our syntax gets grammar—the ability to compose larger expressions and statements out of smaller parts.
Parsing has a long, rich history in computer science that is closely tied to the artificial intelligence community. Many of the techniques used today to parse programming languages were originally conceived to parse human languages by AI researchers who were trying to get computers to talk to us.
It turns out human languages were too messy for the rigid grammars those parsers could handle, but they were a perfect fit for the simpler artificial grammars of programming languages. we flawed humans still manage to use those simple grammars incorrectly, so the parser’s job also includes letting us know when we do by reporting syntax errors.
Static analysis
The first bit of analysis that most languages do is called binding or resolution. For each identifier, we find out where that name is defined and wire the two together. This is where scope comes into play—the region of source code where a certain name can be used to refer to a certain declaration.
If the language is statically typed, this is when we type to check. Once we know where a and b are declared, we can also figure out their types. Then if those types don’t support being added to each other, we report a type error.
Everything up to this point is considered the front end of the implementation. You might guess everything after this is the back end, but no. Back in the days of yore when “front end” and “back end” were coined, compilers were much simpler. Later researchers invented new phases to stuff between the two halves. Rather than discard the old terms, William Wulf and company lumped those new phases into the charming but spatially paradoxical name middle end.
Middle-End of Implementation:
Intermediate representations:
The front end of the pipeline is specific to the source language the program is written in. The back end is concerned with the final architecture where the program will run.
In the middle, the code may be stored in some intermediate representation (IR) that isn’t tightly tied to either the source or destination forms (hence “intermediate”). Instead, the IR acts as an interface between these two languages.
This lets you support multiple source languages and target platforms with less effort. Say you want to implement Pascal, C, and Fortran compilers, and you want to target x86, ARM, and, I dunno, SPARC. Normally, that means you’re signing up to write nine full compilers: Pascal→x86, C→ARM, and every other combination.
Optimization:
Optimization is a huge part of the programming language business. Many language hackers spend their entire careers here, squeezing every drop of performance they can out of their compilers to get their benchmarks a fraction of a percent faster. It can become a sort of obsession.
Back-End of Implementation:
Code generation:
Finally, we are in the back end, descending the other side of the mountain. From here on out, our representation of the code becomes more and more primitive. we will try to make our machine understand our code.
We have a decision to make. Do we generate instructions for a real CPU or a virtual one? If we generate real machine code, we get an executable that the OS can load directly onto the chip. Native code is lightning fast, but generating it is a lot of work. Today’s architectures have piles of instructions, complex pipelines, and enough historical baggage to fill a 747’s luggage bay.
Speaking the chip’s language also means your compiler is tied to a specific architecture. If your compiler targets x86 machine code, it’s not going to run on an ARM device. All the way back in the ’60s, during the Cambrian explosion of computer architectures, that lack of portability was a real obstacle.
To get around that, many hackers made their compilers produce virtual machine code. Instead of instructions for some real chip, they produced code for a hypothetical, idealized machine. we generally call it bytecode because each instruction is often a single byte long.
These synthetic instructions are designed to map a little more closely to the language’s semantics, and not be so tied to the peculiarities of any one computer architecture and its accumulated historical cruft. You can think of it as a dense, binary encoding of the language’s low-level operations.
Virtual machine:
If your compiler produces bytecode, your work isn’t over once that’s done. Since there is no chip that speaks that bytecode, it’s your job to translate.
You have two options. You can write a little mini-compiler for each target architecture that converts the bytecode to native code for that machine.
You still have to do work for each chip you support, but this last stage is pretty simple and you get to reuse the rest of the compiler pipeline across all of the machines you support. You’re basically using your bytecode as an intermediate representation.
outro:
These are the processes behind making a Low-level programming language.
Then How High-Level languages are made?🤔
well, They use some short paths to create one, like Transpiling in between. See it in the mountain image above.
Hope this is Informative and would have given a simple understanding of how a programming language is designed.
Thank you😊
Happy learning
-JHA