Exploratory Data analysis using pandas profiling

Hello everyone,
In this article, we are going to explore how to perform exploratory data analysis using an open-source python module called pandas-profiling.
Usually analyzing a dataset or preparing a data report of a data set would be a tiring process. starting with producing numeric analysis to map analysis there is a lot of work to do. But let's see how to perform EDA with simple steps using pandas-profiling.
First of all, let us see
WHAT IS EDA - EXPLORATORY DATA ANALYSIS
let's say you want to buy a car 🏎, before buying you will see a review of various cars online and consider various aspects like brand, mileage, durability, etc... then you will analyze what to buy and what not to buy from the data you have collected. likewise, before training an ML model we would do an analysis of the dataset, basically to reduce redundancy and anomalies if any and to have an overview of the dataset. That analysis is called exploratory data analysis(EDA).
Exploratory Data Analysis refers to the critical process of performing initial investigations on data so as to discover patterns, spot anomalies, test hypotheses, and check assumptions with the help of summary statistics and graphical representations.
so it is better to perform exploratory data analysis before training a model for production purposes so that you will get a better understanding of the data you are working on.
PANDAS-PROFILING
Pandas profiling is an open-source Python module with which we can quickly do an exploratory data analysis with just a few lines of code. it also generates interactive reports in a web format that can be presented to any person, even if they don’t know to program them.
In short, what pandas profiling does is save us all the work of visualizing and understanding the distribution of each variable. It generates a report with all the information easily available.
Lets us get to code,
I use Jupyter notebook and I would recommend using it. Other environments like google collab sometimes don't support every feature provided by pandas-profiling.
the first step is to install the dependencies
pip install pandas-profiling
I hope you have installed pandas and NumPy already. if not install them too.
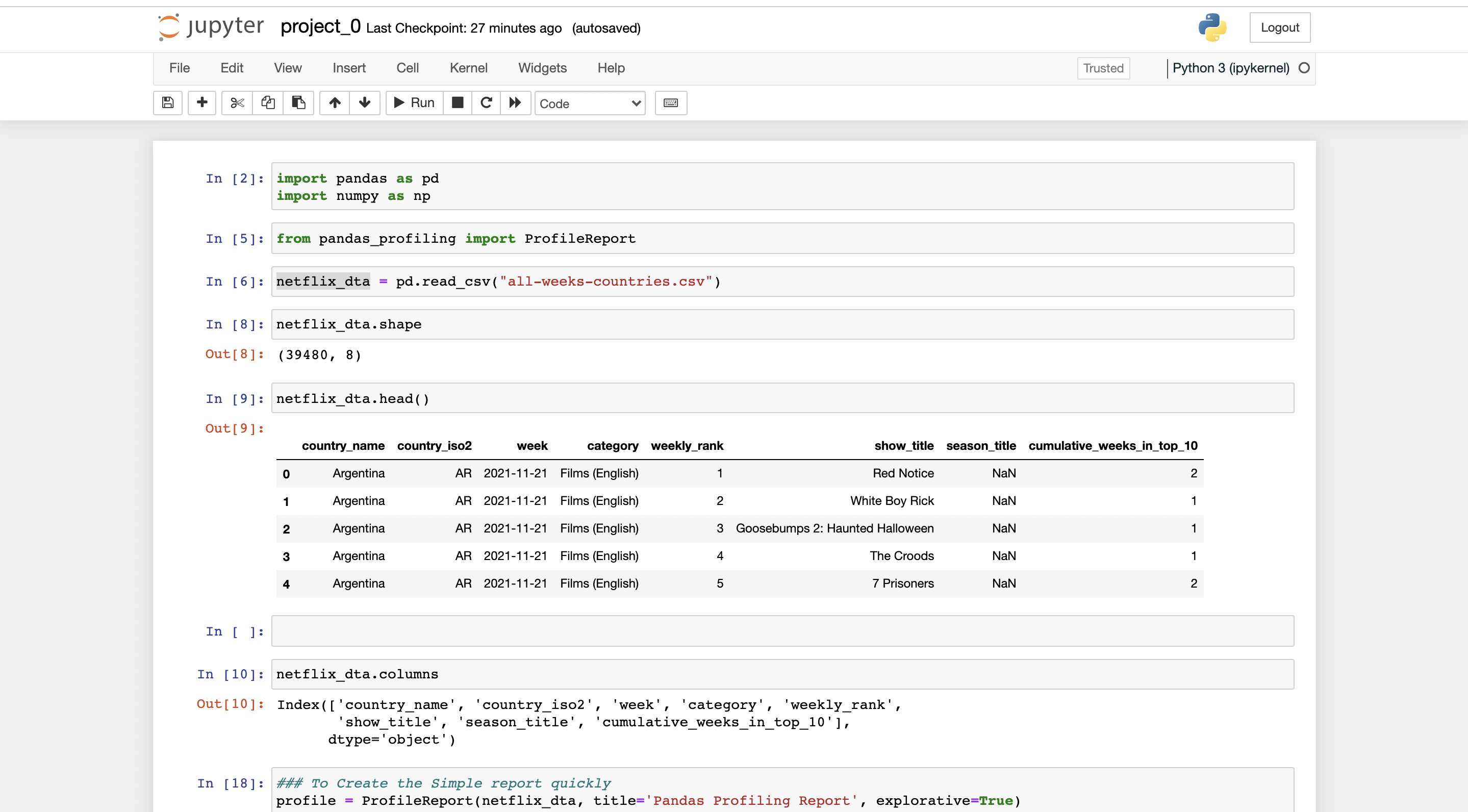
import pandas as pd
import numpy as np
from pandas_profiling import ProfileReport
download any dataset from kaggle.
dta = pd.read_csv("file-name.csv")
//to check if the dataset is loaded
dta.shape
dta.head()
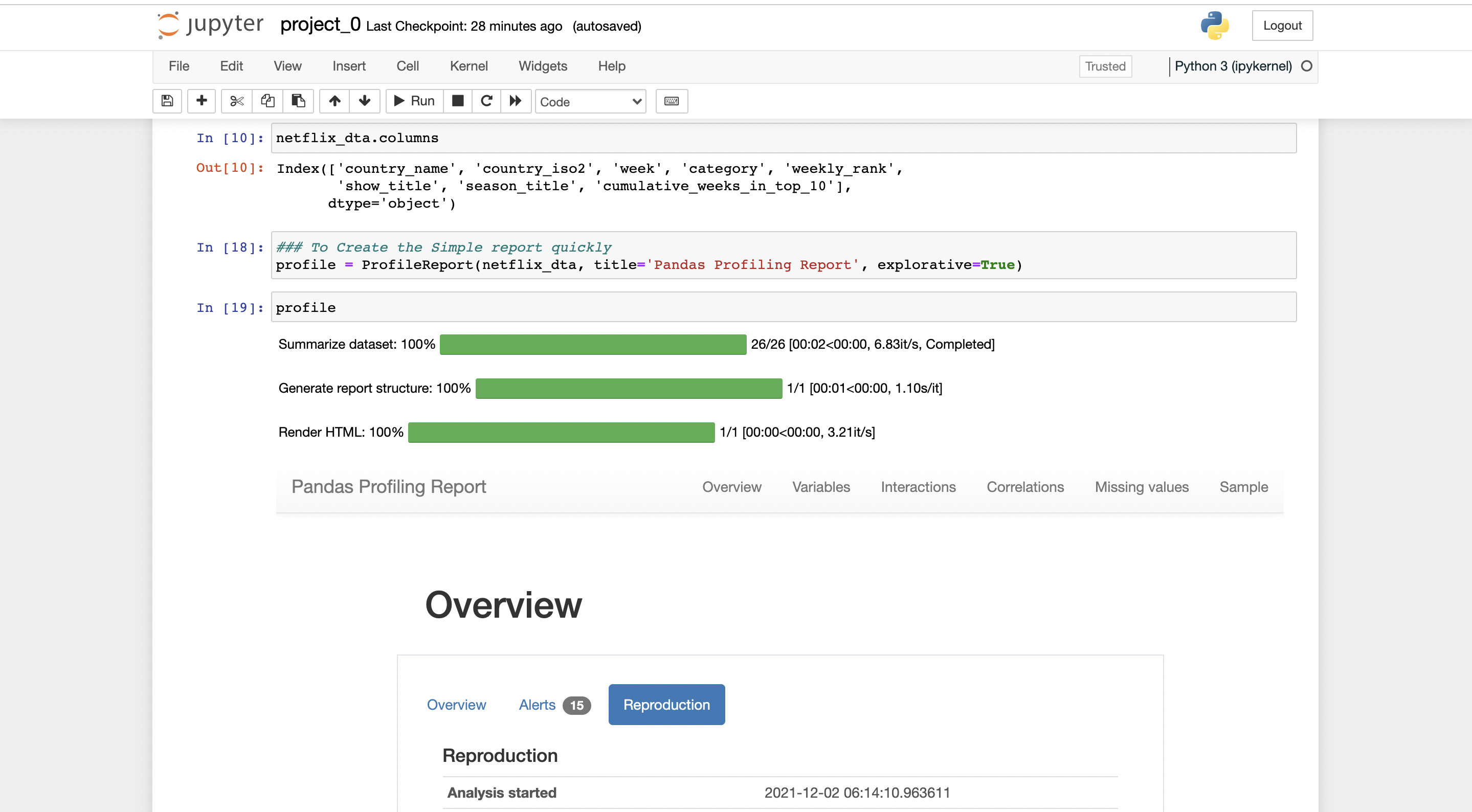
//to create a report
profile = ProfileReport(dta, 'Pandas profiling report', explorative = True)
//, at last, performs the above code and run the cell
profile
There will be a report generated by pandas-profiling.
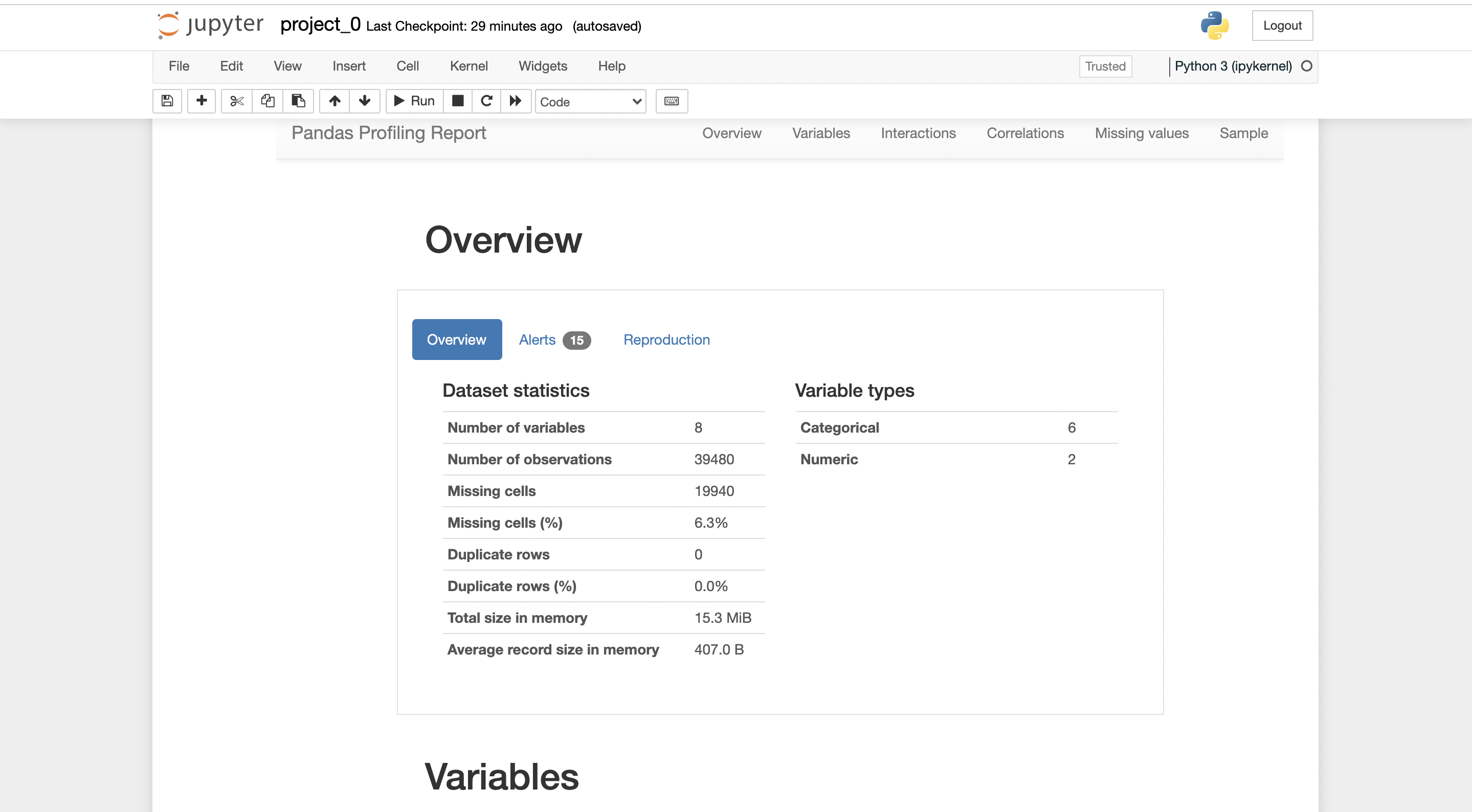
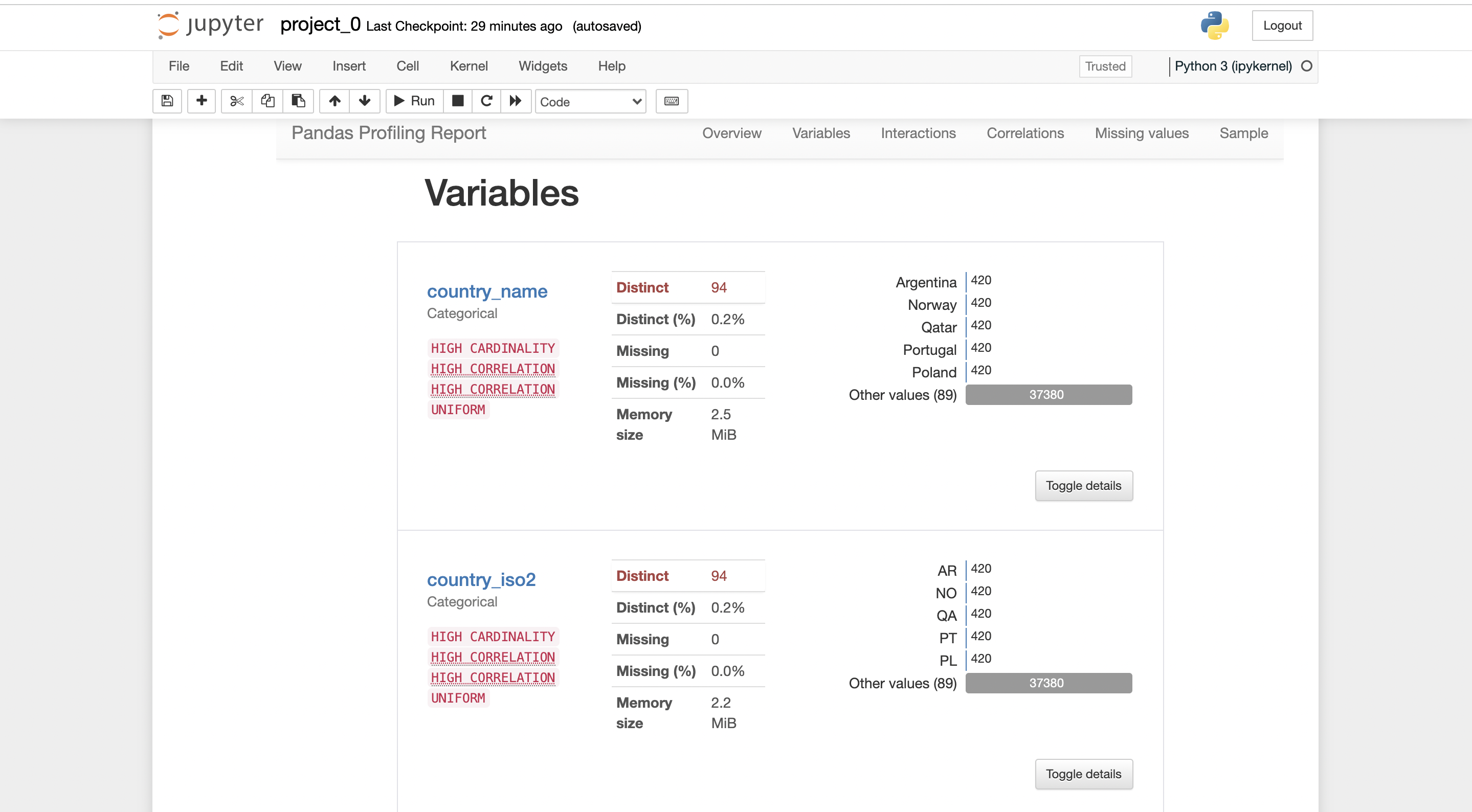
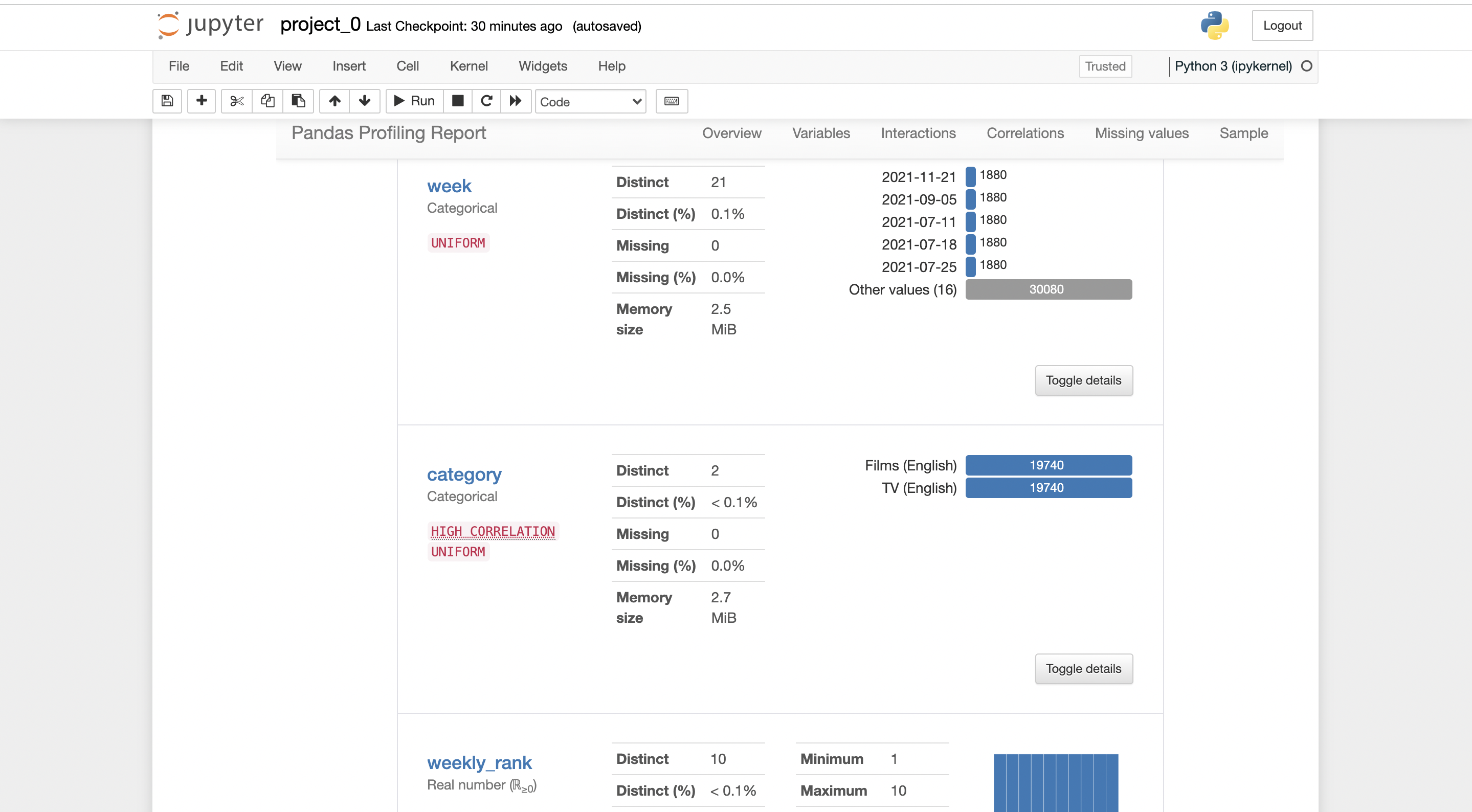
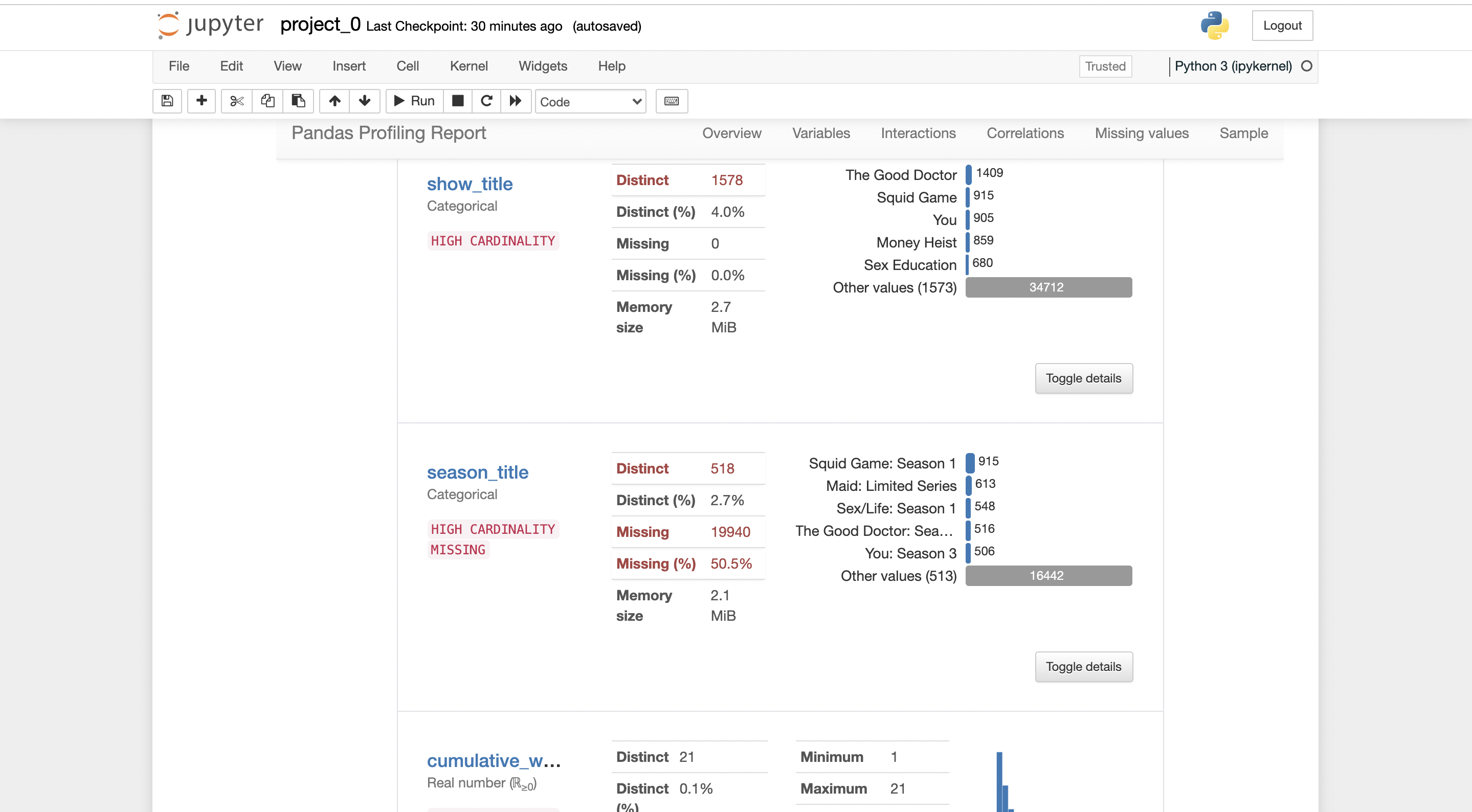
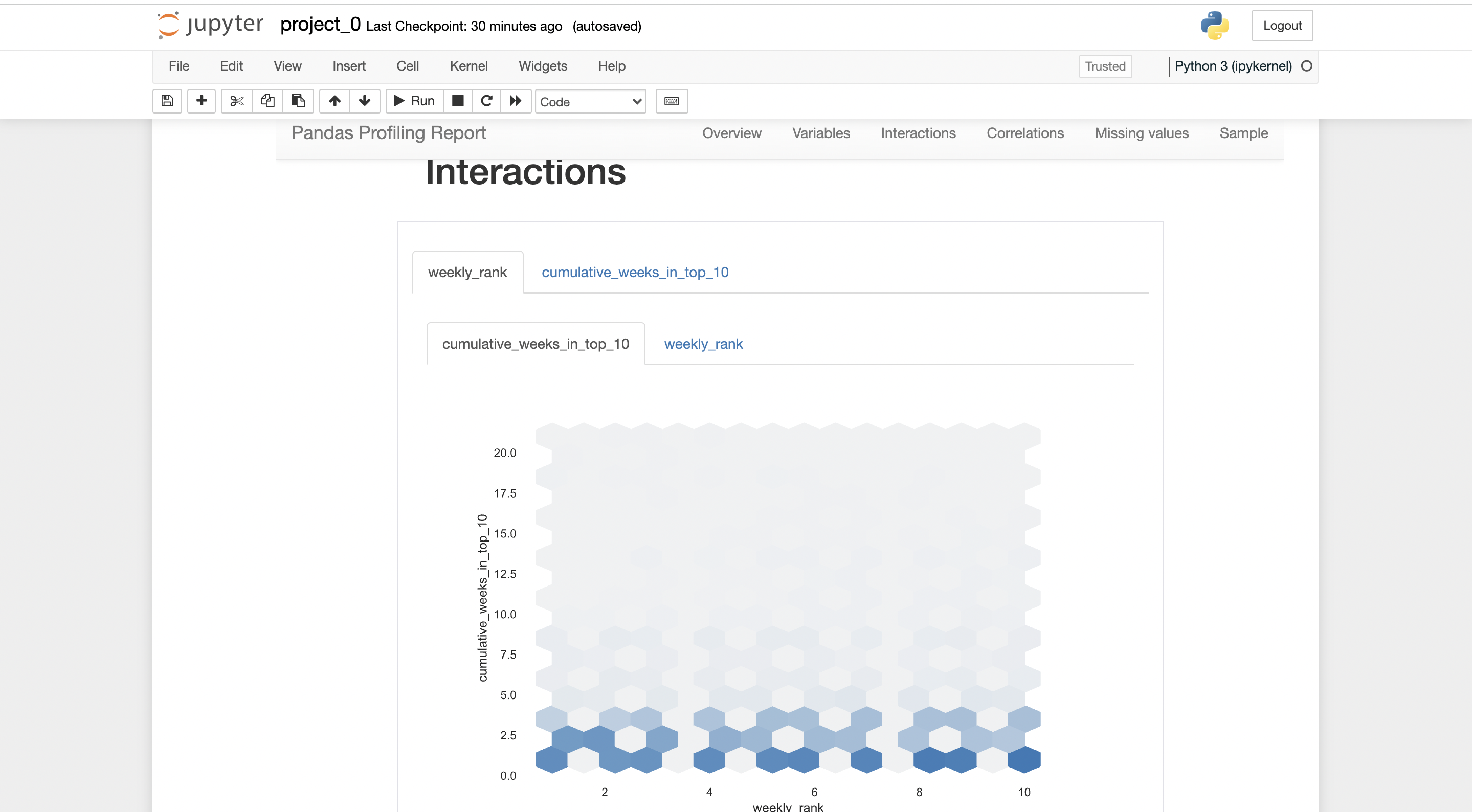
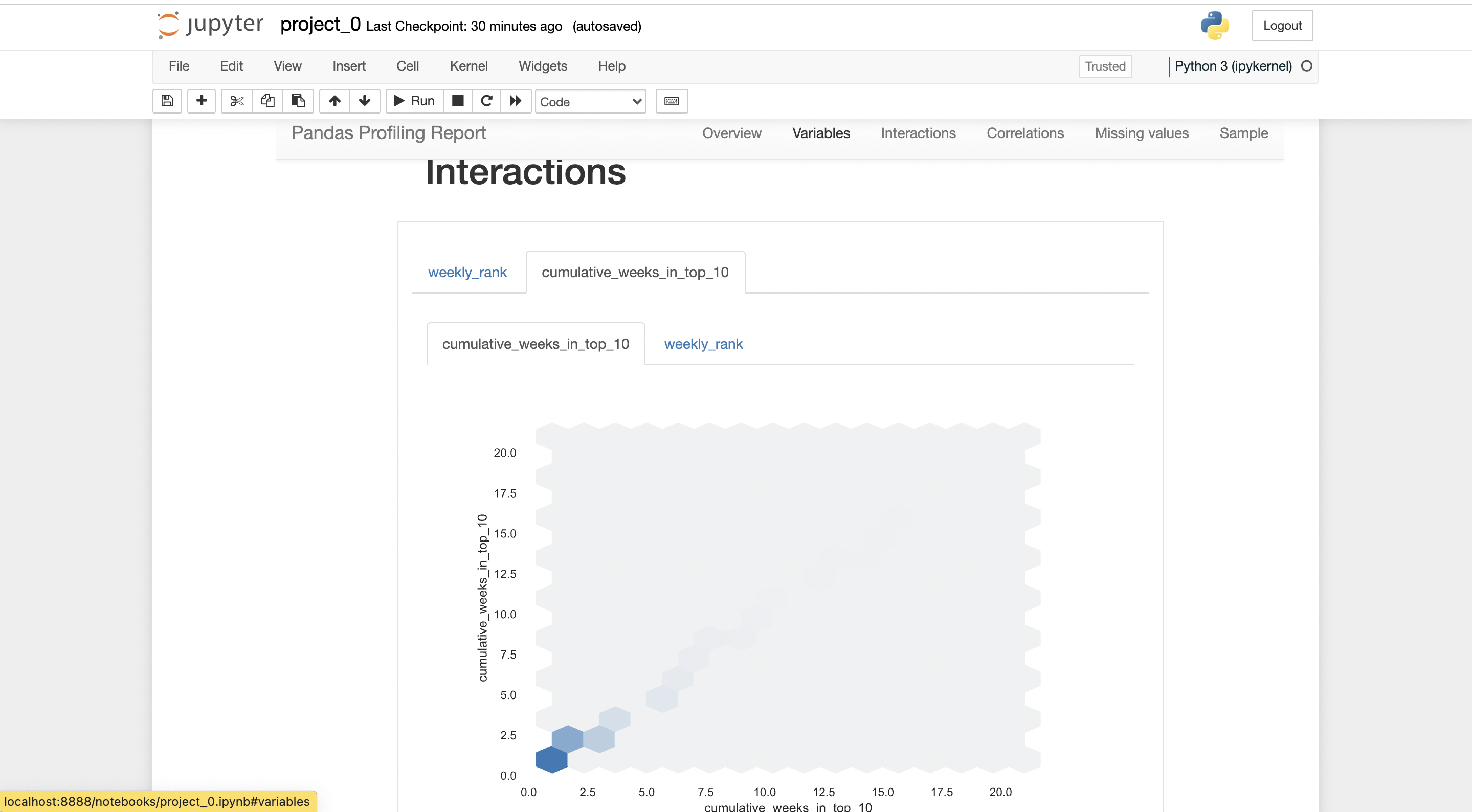
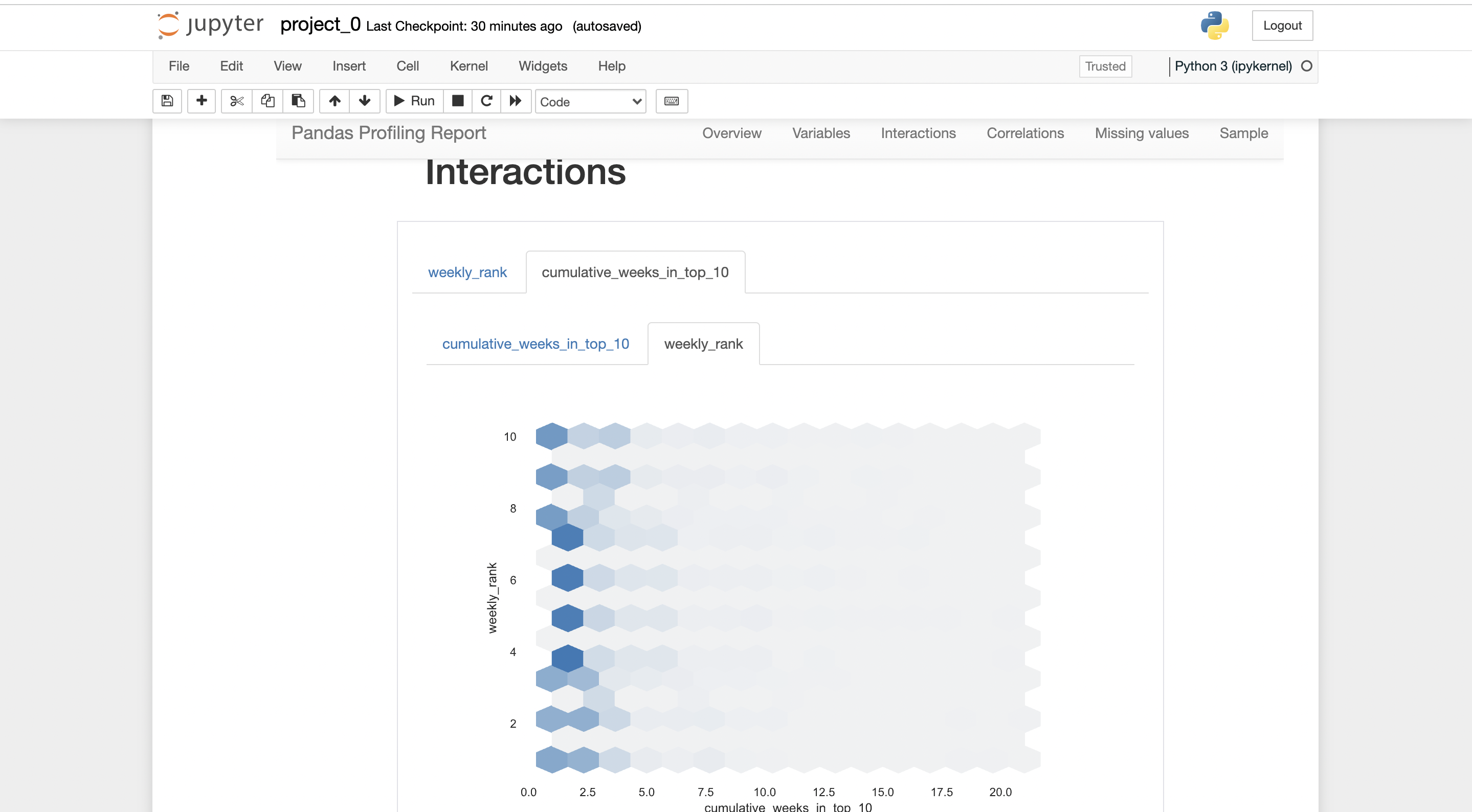
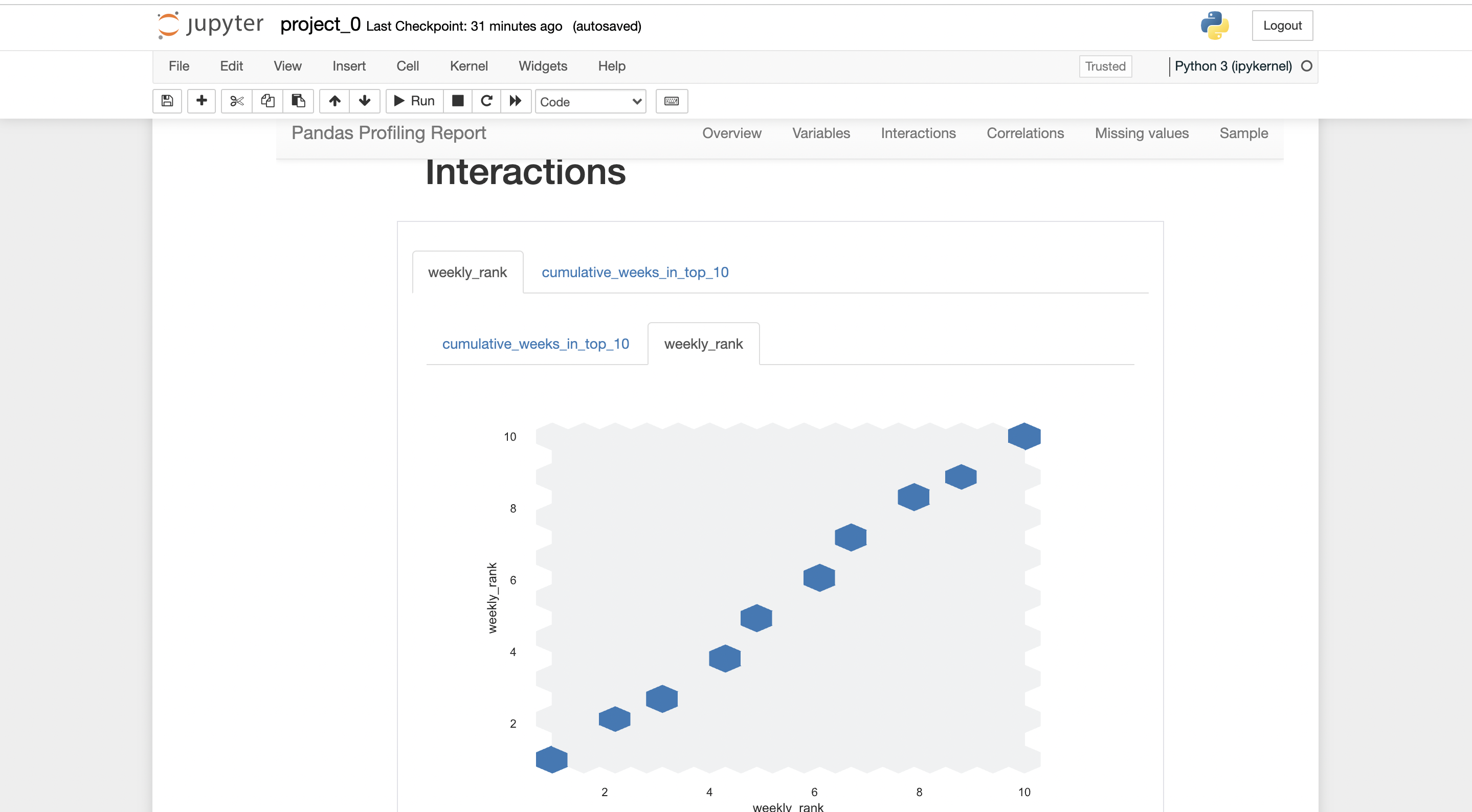
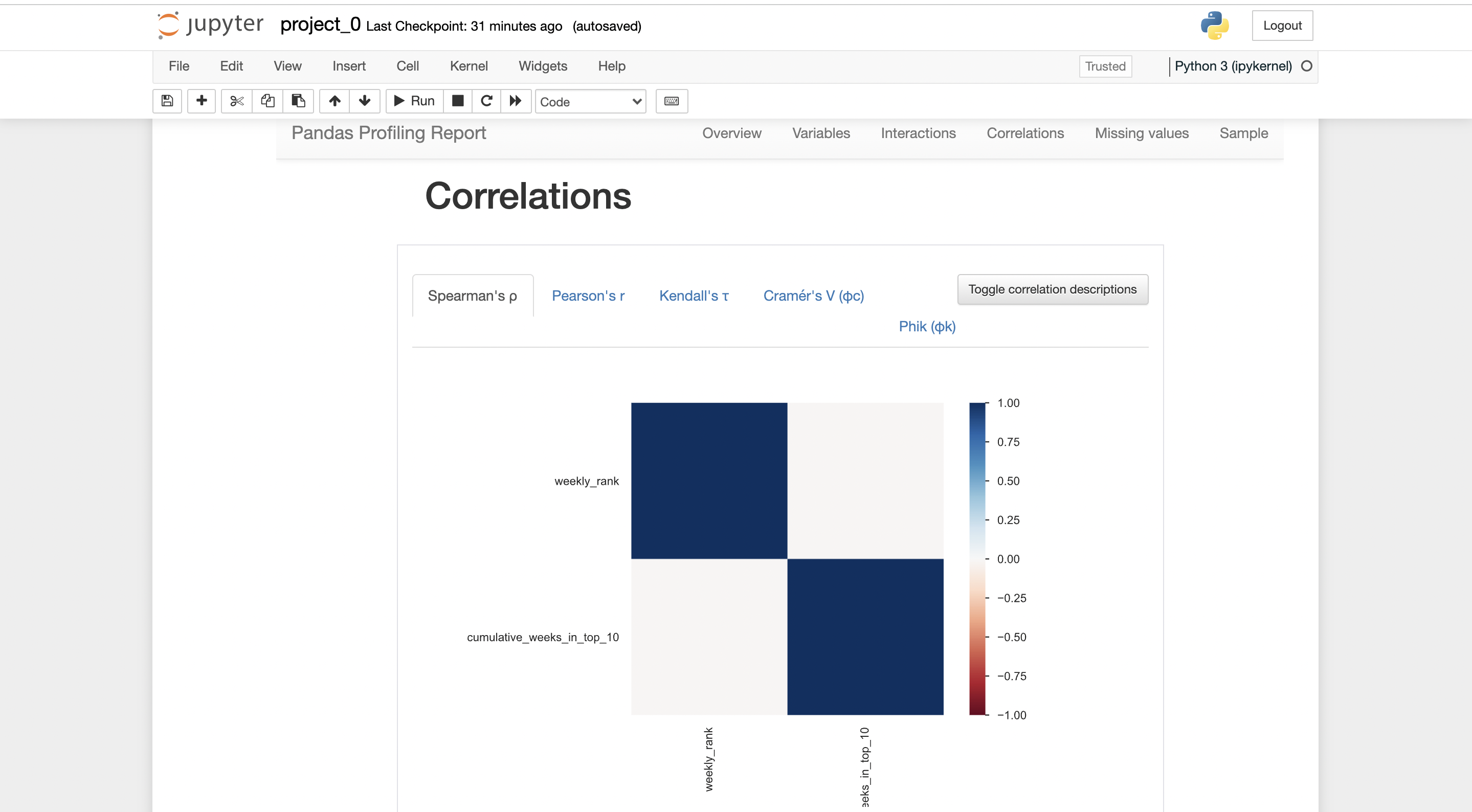
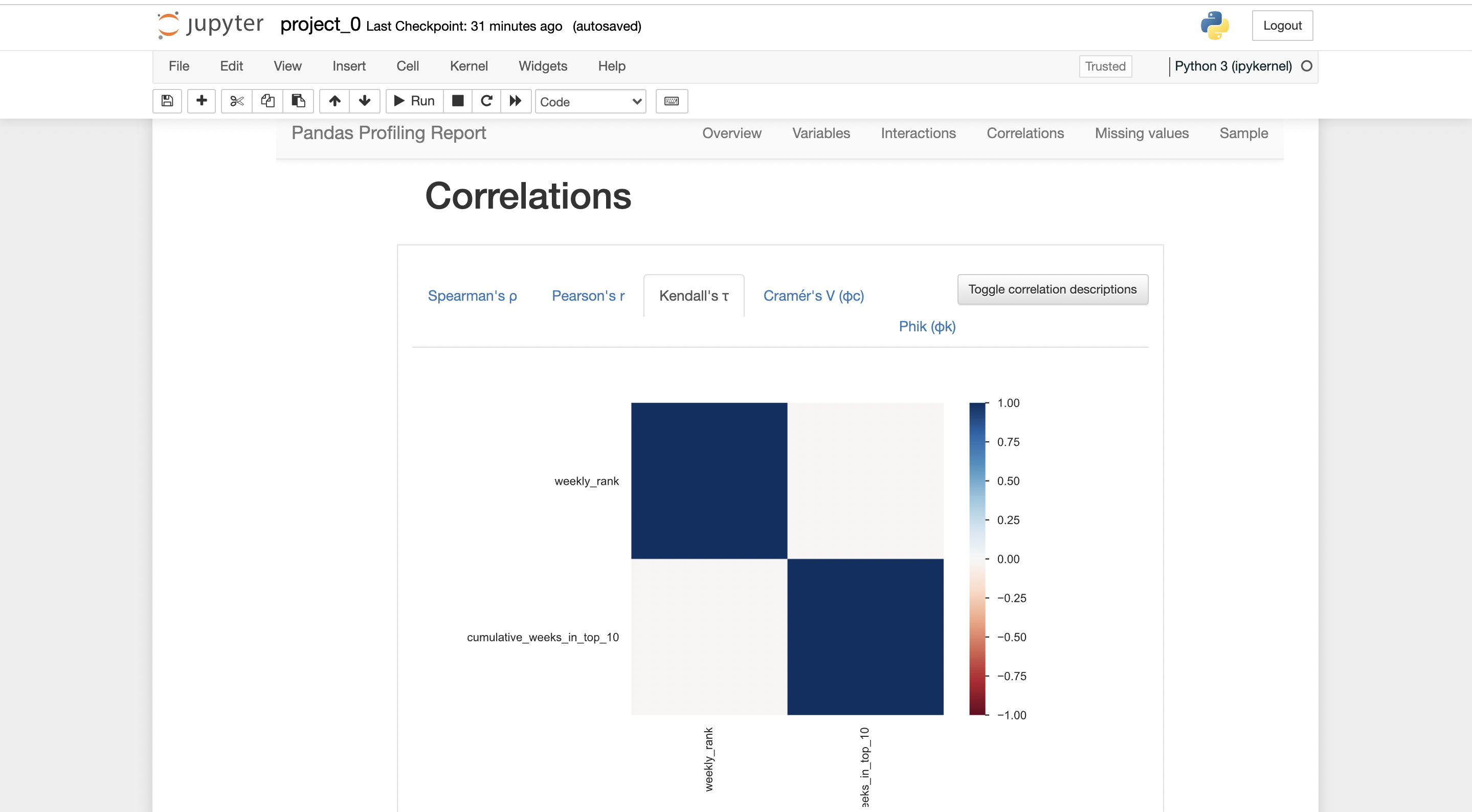
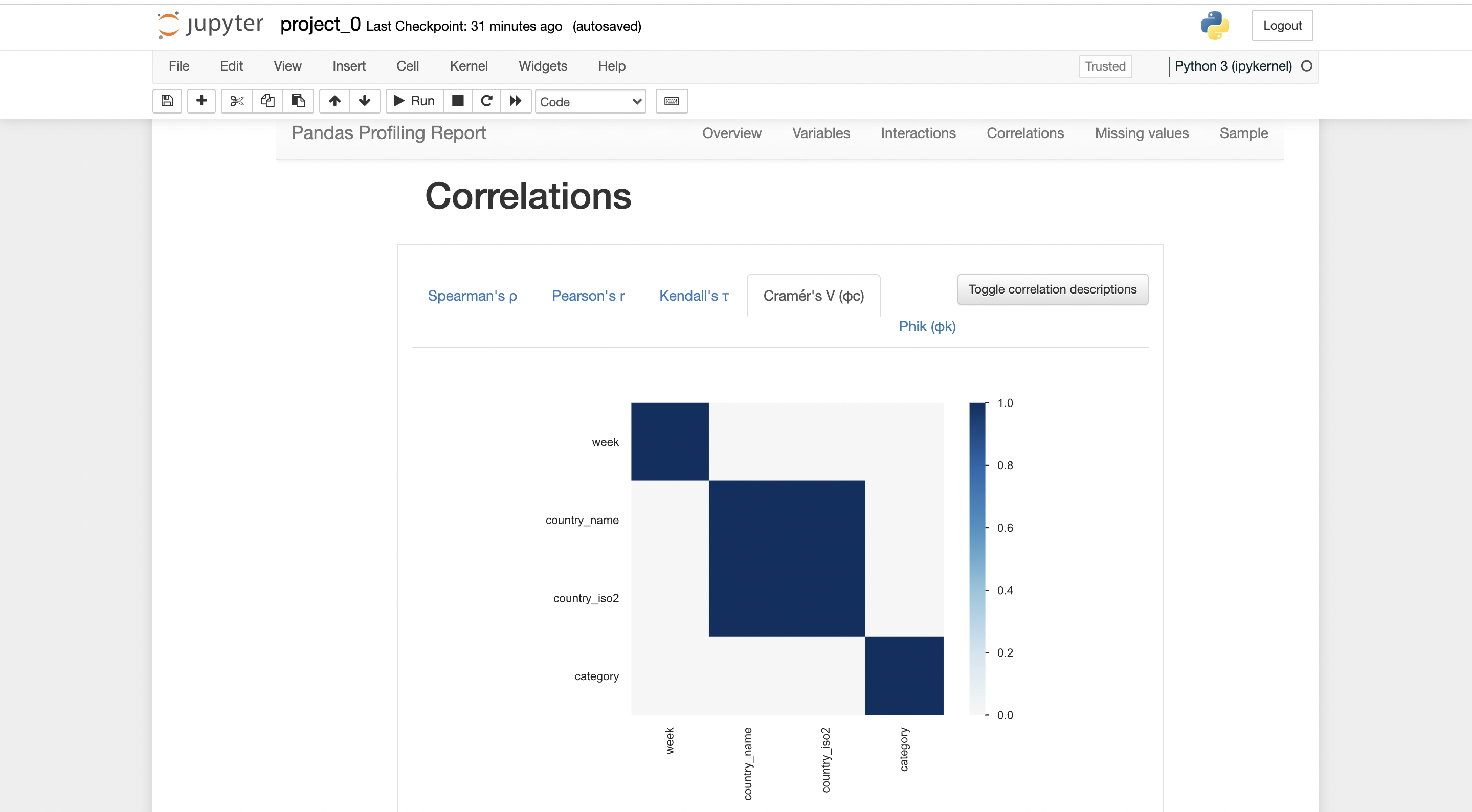
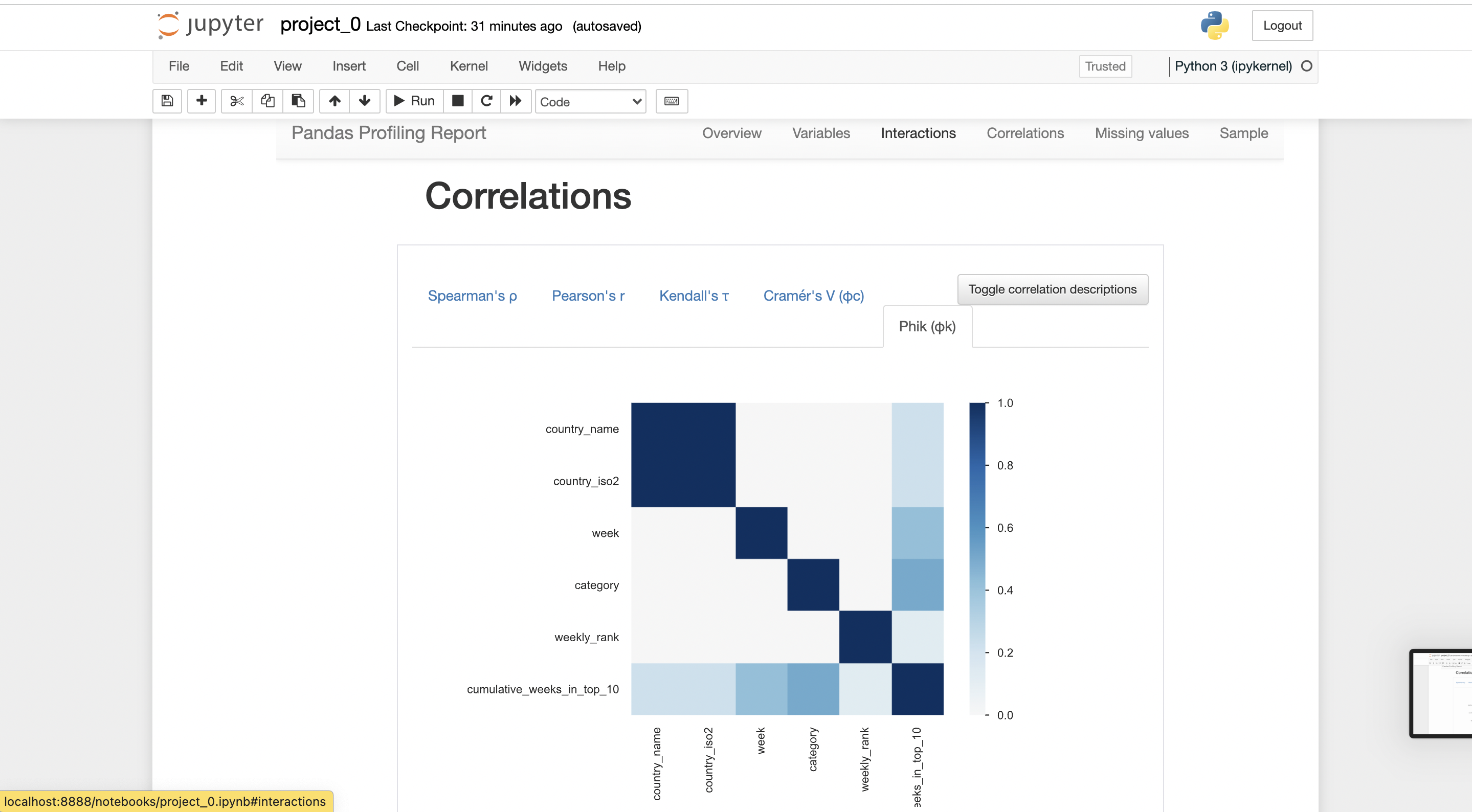
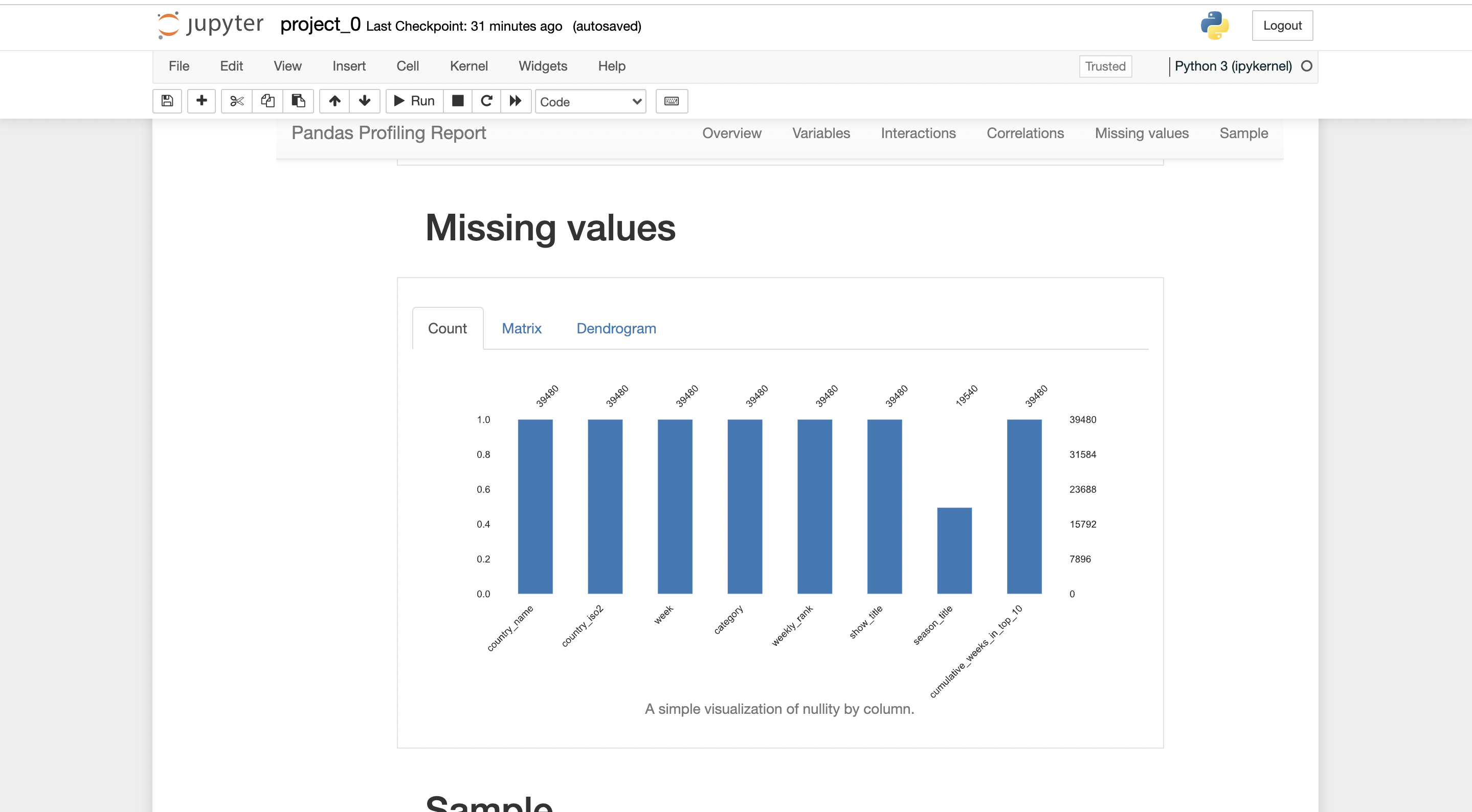
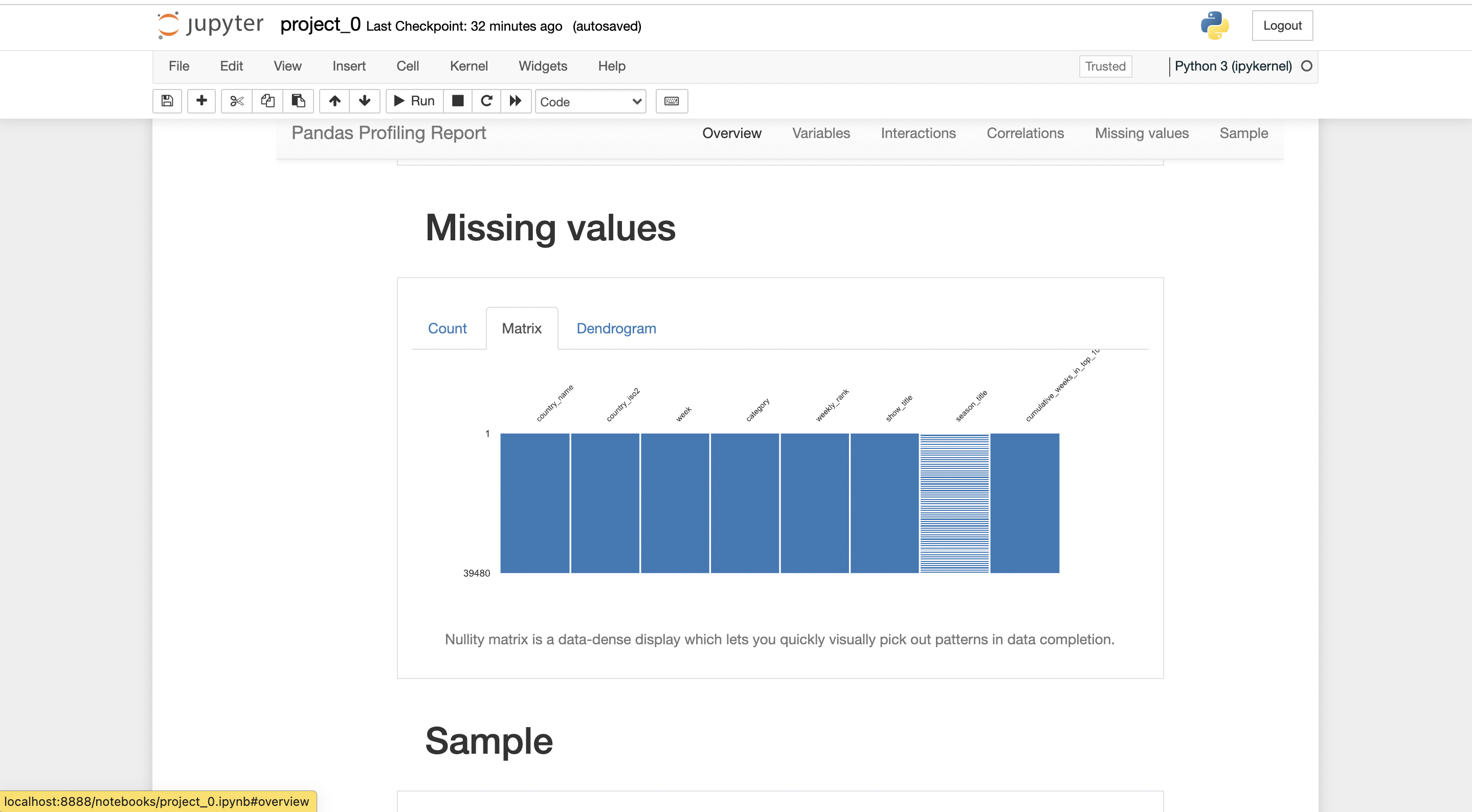
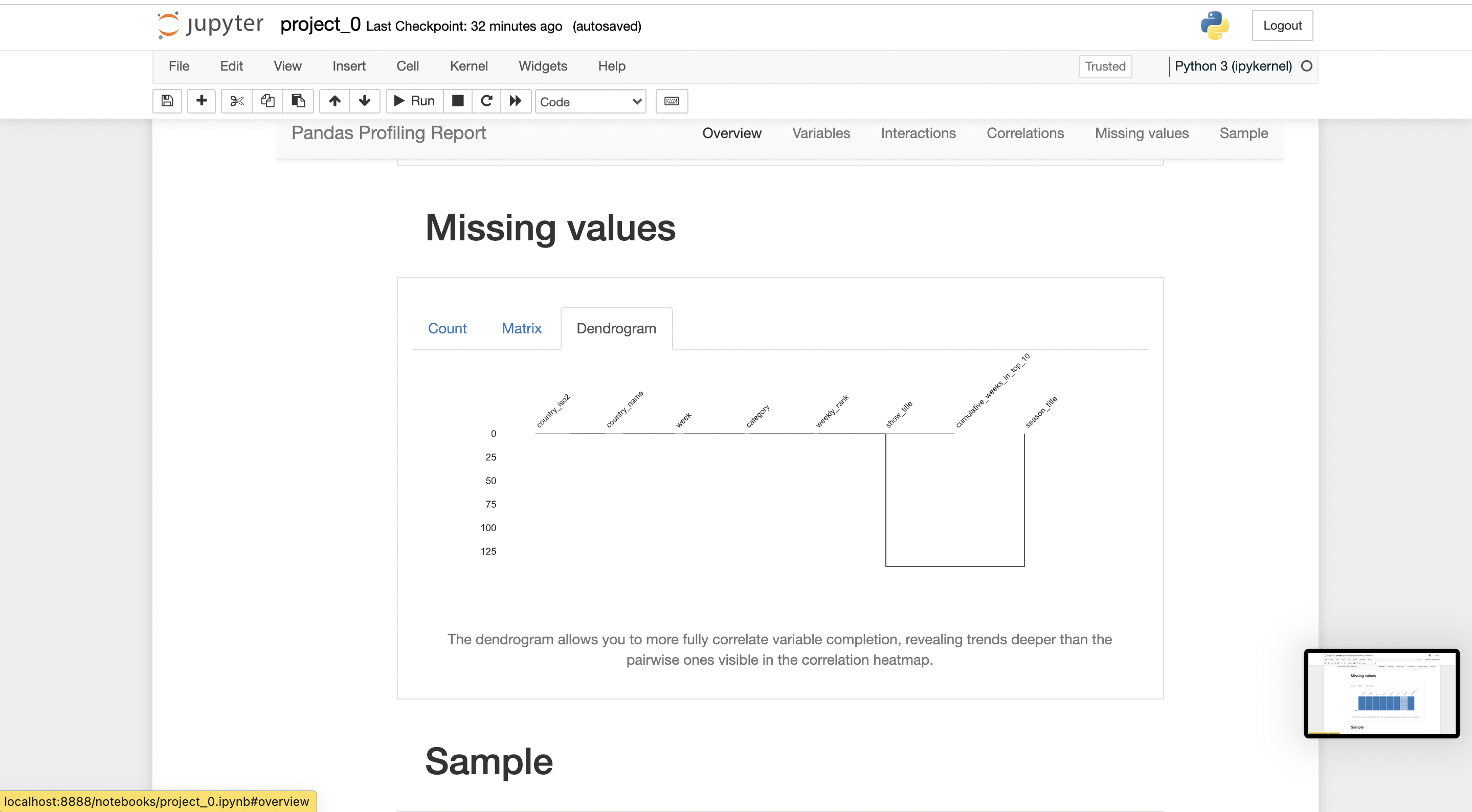
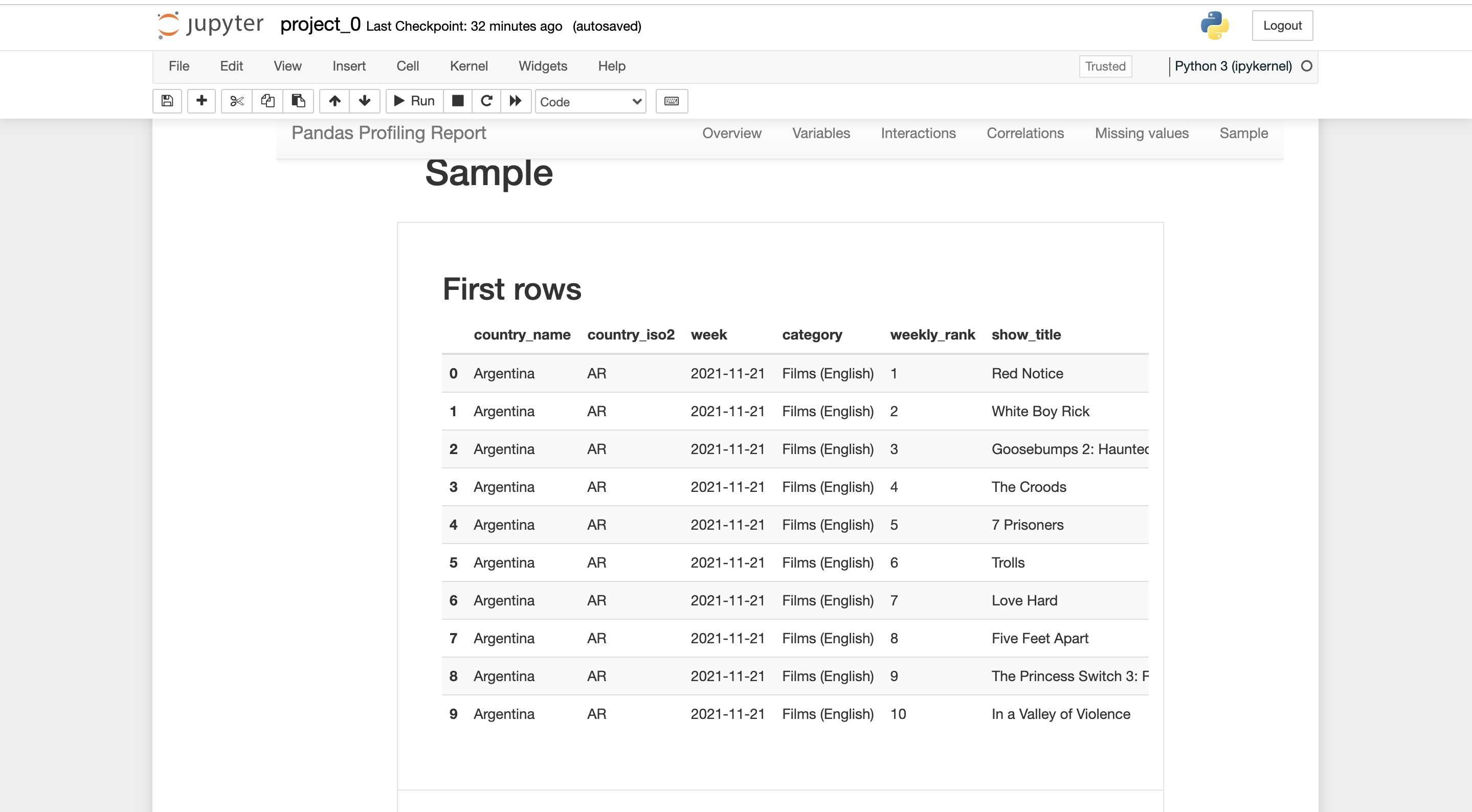
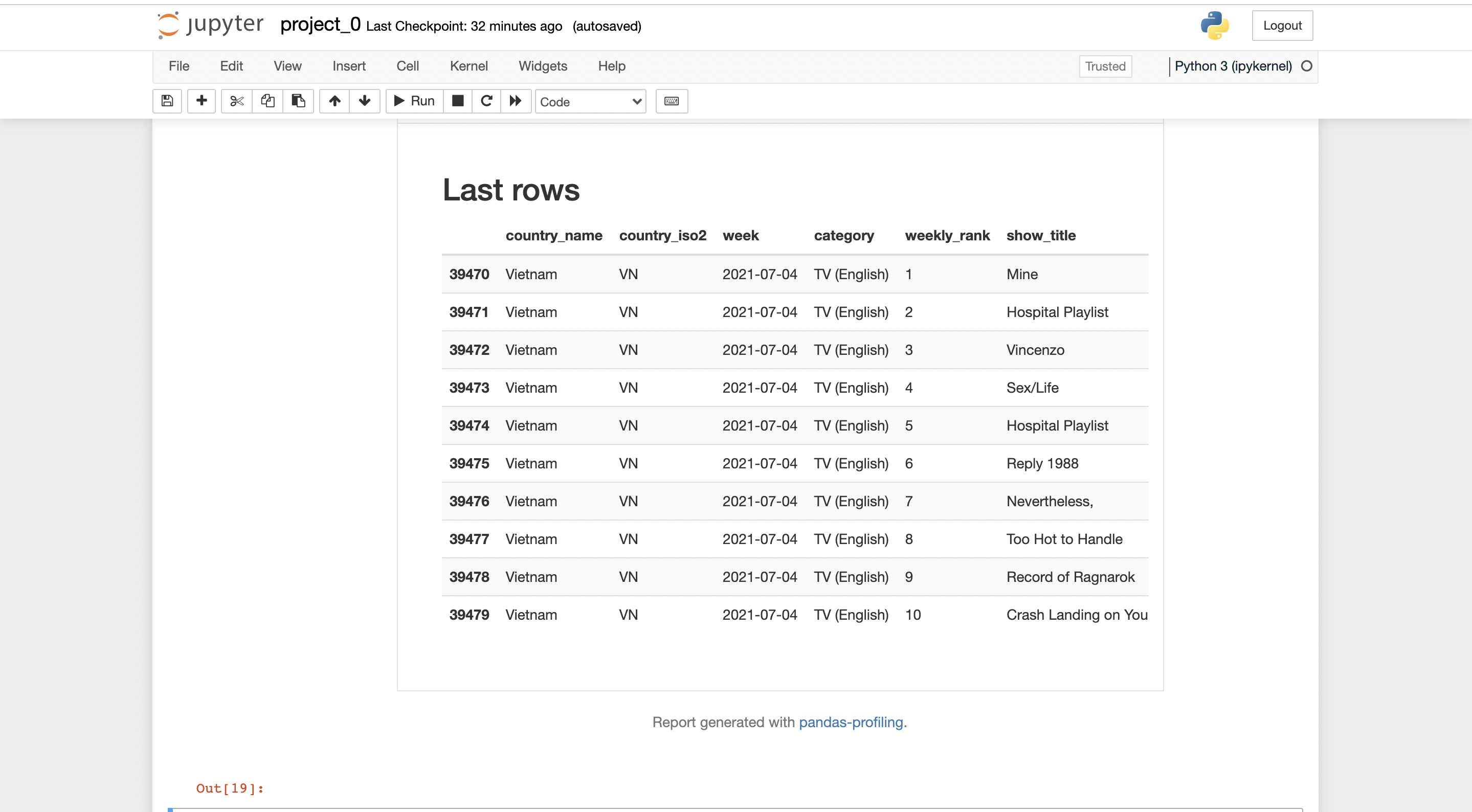
you can export the report in .html form, where it can be shared with anybody easily.
profile.to_file("any_name.html")
the file will be stored in the directory you store your notebook
OUTRO:
I hope you have learned something new and efficient. like pandas-profiling there are quite a few modules in python like sweetviz, D-Tale, which make our lives easier to perform exploratory data analysis, especially for huge datasets.
related sources:
Thank you for reading 😊
HAPPY LEARNING
-JHA




